
In today's data-driven world, businesses often need to match and merge data from various sources to create a unified view. This process is critical in industries like marketing, healthcare, finance, and more. When it comes to matching algorithms, two primary methods stand out: deterministic and probabilistic matching. But what is the difference between the two, and when should each be used? Let’s dive into the details and explore both approaches.
- What Is Deterministic Matching?
Deterministic matching refers to a method of matching records based on exact or rule-based criteria. This approach relies on specific identifiers like Social Security numbers, email addresses, or customer IDs to find an exact match between data points.
- How It Works: The deterministic matching algorithm looks for fields that perfectly match across different datasets. If all specified criteria are met (e.g., matching IDs or emails), the records are considered a match.
- Example: In healthcare, matching a patient’s medical records across systems based on their unique patient ID is a common use case for deterministic matching.
- Advantages: High accuracy when exact matches are available; ideal for datasets with consistent, structured, and well-maintained records.
- Limitations: Deterministic matching falls short when data is inconsistent, incomplete, or when unique identifiers (such as email or customer IDs) are not present.
- What Is Probabilistic Matching?
Probabilistic matching is a more flexible approach that evaluates the likelihood that two records represent the same entity based on partial, fuzzy, or uncertain data. It uses statistical algorithms to calculate probabilities and scores to determine the best possible match.
- How It Works: A probabilistic matching algorithm compares records on multiple fields (such as names, addresses, birth dates) and assigns a probability score based on how similar the fields are. A match is confirmed if the score exceeds a pre-defined threshold.
- Example: In marketing, matching customer records from different databases (which may have variations in how names or addresses are recorded) would benefit from probabilistic matching.
- Advantages: It handles discrepancies in data (e.g., misspellings, name changes) well and is effective when exact matches are rare or impossible.
- Limitations: While more flexible, probabilistic matching is less precise and may yield false positives or require additional human review for accuracy.
- Deterministic vs. Probabilistic Matching: Key Differences
Understanding the differences between deterministic vs probabilistic matching is essential to selecting the right approach for your data needs. Here’s a quick comparison:
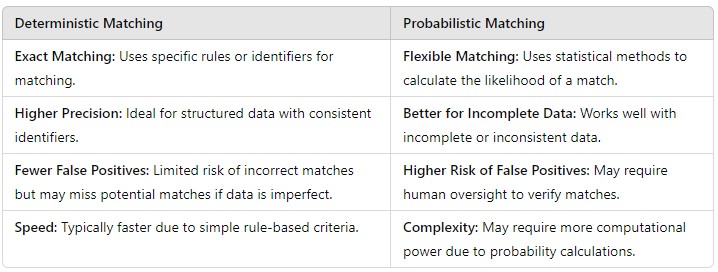
- Real-World Applications: Deterministic vs. Probabilistic Matching
Deterministic Matching in Action
- Finance: Banks often use deterministic matching when reconciling transactions, relying on transaction IDs or account numbers to ensure precision in identifying related records.
- Healthcare: Hospitals utilize deterministic matching to link patient records across departments using unique identifiers like medical record numbers.
Probabilistic Matching in Action
- Marketing: Marketers often deal with messy customer data that includes inconsistencies in name spelling or address formatting. Here, probabilistic vs deterministic matching comes into play, with probabilistic matching being favored to find the most likely matches.
- Insurance: Insurance companies frequently use probabilistic matching to detect fraud by identifying subtle patterns in data that might indicate fraudulent claims across multiple policies.
- When to Use Deterministic vs. Probabilistic Matching?
The choice between deterministic and probabilistic matching depends on the nature of the data and the goals of the matching process.
Use Deterministic Matching When:
- Data is highly structured: If you have clean and complete datasets with consistent identifiers (such as unique customer IDs or social security numbers).
- Precision is critical: When the cost of incorrect matches is high (e.g., in financial transactions or healthcare data), deterministic matching is a safer choice.
- Speed is a priority: Deterministic matching is faster due to the simplicity of its rule-based algorithm.
Use Probabilistic Matching When:
- Data is messy or incomplete: Probabilistic matching is ideal when dealing with datasets that have discrepancies (e.g., variations in names or missing identifiers).
- Flexibility is needed: When you want to capture potential matches based on similarities and patterns rather than strict rules.
- You’re working with unstructured data: In scenarios where exact matches are rare, probabilistic matching provides a more comprehensive way to link related records.
- Combining Deterministic and Probabilistic Approaches
In many cases, businesses might benefit from a hybrid approach that combines both deterministic and probabilistic matching methods. This allows for more flexibility by using deterministic matching when exact identifiers are available and probabilistic methods when the data lacks structure or consistency.
Example: In identity resolution, a company may first apply deterministic matching to link accounts using unique identifiers (e.g., email or phone number) and then apply probabilistic matching to resolve any remaining records with partial data or variations in names.
Conclusion
Choosing between deterministic vs probabilistic matching ultimately depends on the specific needs of your data matching process. Deterministic matching provides high precision and works well with structured data, while probabilistic matching algorithms offer flexibility for dealing with unstructured or incomplete data.
By understanding the strengths and limitations of each approach, businesses can make informed decisions about which algorithm to use—or whether a combination of both is necessary—to achieve accurate and efficient data matching. In today’s increasingly complex data landscape, mastering these techniques is key to unlocking the full potential of your data.








